ChatGPTでお問い合わせチャットBotを作るには
ChatGPTのようなLLMとSlackを用いて、お問い合わせのチャットBotを開発できます。
従来のフローチャートを用いたチャットBotと違い、LLMを使用した場合は質問に対して適切な回答を自動で生成できます。
OpenAIのPlaygroundで試すことができます。
https://platform.openai.com/playground
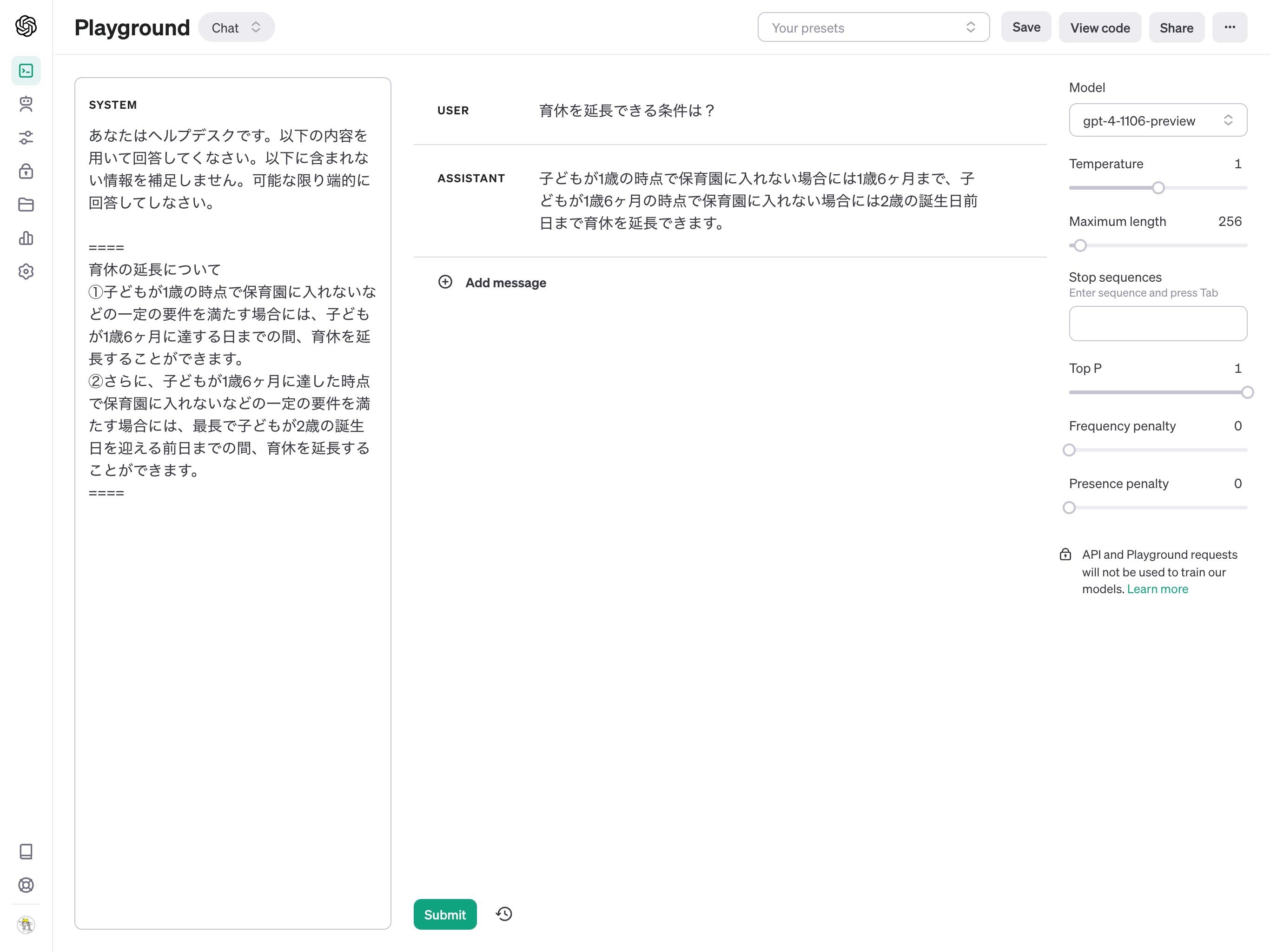
例えば、社内に以下のような情報があったとして、これを元に社内向けのチャットBotを開発します。
育休の延長について
①子どもが1歳の時点で保育園に入れないなどの一定の要件を満たす場合には、子どもが1歳6ヶ月に達する日までの間、育休を延長することができます。
②さらに、子どもが1歳6ヶ月に達した時点で保育園に入れないなどの一定の要件を満たす場合には、最長で子どもが2歳の誕生日を迎える前日までの間、育休を延長することができます。
これに対して以下のような質問をすると要約された解答をできます。ただ、人間と同じく間違った回答もするので参考にした元の文章も回答すると良いです。
USER: 育休を延長できる条件は?
ASSISTANT: 子どもが1歳の時点で保育園に入れない場合には1歳6ヶ月まで、子どもが1歳6ヶ月の時点で保育園に入れない場合には2歳の誕生日前日まで育休を延長できます。
また、情報が不足している場合は、回答不能と判断し応答できます。
USER: 有給休暇の付与日は?
ASSISTANT: 有給休暇の付与日に関する情報は提供されていません。現在の情報ではその質問には答えられません。
この場合は、以下のようなプロンプトを使用してチャットBotを作成しました。
あなたはヘルプデスクです。以下の内容を用いて回答してくなさい。以下に含まれない情報を補足しません。可能な限り端的に回答してしなさい。
====
育休の延長について
①子どもが1歳の時点で保育園に入れないなどの一定の要件を満たす場合には、子どもが1歳6ヶ月に達する日までの間、育休を延長することができます。
②さらに、子どもが1歳6ヶ月に達した時点で保育園に入れないなどの一定の要件を満たす場合には、最長で子どもが2歳の誕生日を迎える前日までの間、育休を延長することができます。
====
ChatGPTに追加の情報を与える
ChatGPTは質問の内容を読み取り回答を作成できますが、社内の情報は学習していません。
全てのデータを最初に与える
Assistants APIを使用すればトークンの制限の許す限り情報を与えることができます。
データがPDFのようなファイルであったとしてもRetrievalを使用すれば与えることができます。
https://platform.openai.com/docs/assistants/tools/knowledge-retrieval
この方法は最も簡単ですが、会話のたびにトークンが消費され費用がかかります。
数回の会話で終わるようなお問い合わせの場合は少し無駄が発生します。
必要に応じてデータを取得する
質問の内容に応じてデータベースから情報を取得することができます。
また、Notionにデータがある場合はAPIなどを使用することもできます。
https://developers.notion.com/
ベクトル検索を用いて情報を取得する
文字列をベクトル化して、ベクトル同士の距離を計算することで、文章の類似度を計算することができます。
お問い合わせには、2つの情報が必要です。
- 解答に必要な情報
- 質問の内容
このうち、前者は事前にベクトル化しておきます。
どのようにベクトル化するか
文章はOpenAIのAPIを使えば事前にベクトル化できます。
https://platform.openai.com/docs/guides/embeddings
const embeddingResponse = await openai.embeddings.create({
model: "text-embedding-ada-002",
input: "文章"
})
このようなデータが返ってきます。
{
object: 'embedding',
index: 0,
embedding: [
0.017697312, -0.018313898, 0.021095091, -0.0065430203,
0.006441349, -0.0026778828, -0.0024811001, -0.009662024,
0.00078221067, -0.025568614, -0.0065725376, -0.011321557,
-0.0010249092, -0.02278742, -0.008901131, 0.021908458,
0.042347606, -0.028572828, 0.033557985, -0.0372575,
-0.020281723, 0.029622335, -0.0022662792, -0.0005575506,
-0.014601266, 0.026657479, 0.010626258, -0.027575796,
0.014942356, -0.03521096, 0.024532227, 0.0029025427,
-0.003781505, 0.003251832, -0.02278742, -0.02018989,
0.0015185055, -0.020872071, 0.017959688, -0.0069464245,
0.019533949, -0.013420571, 0.019114146, 0.007858184,
-0.020137416, 0.03720502, -0.018012164, 0.004653908,
-0.013289383, 0.009439004, 0.032193627, 0.006939865,
-0.008907691, -0.033216897, -0.027497083, -0.0033321849,
-0.038438194, 0.017461173, -0.0045423973, -0.013223789,
0.009465241, 0.038989186, -0.024689652, 0.012449777,
-0.011157571, -0.0013487805, -0.022826778, -0.0050048367,
-0.023404006, -0.02085895, -0.0017054488, 0.027838174,
0.007923778, -0.02854659, 0.028494116, -0.0078057083,
-0.011308438, -0.014247058, -0.012469456, 0.009721058,
0.0111838095, -0.019442117, 0.00039868968, -0.02707728,
-0.010698412, 0.022354499, -0.018484442, 0.02155425,
0.0151653765, -0.019547068, -0.018589392, 0.0034010587,
-0.00035277373, 0.016555972, -0.0029418992, -0.009714499,
0.011229725, 0.026618121, 0.010147421, -0.053052578,
... 1436 more items
]
}
ベクトル化したデータはベクトル検索に対応したデータベースに書き込みます。
PostgreSQLのpgvectorなどが使用できます。
https://github.com/pgvector/pgvector/
supabaseを使用する
supabaseはpgvectorに対応したPostgreSQLのデータベースを提供しています。しかも無料で使えます。
GitHubのActionsを用いてリポジトリ内のマークダウンをベクトル化してデータベースに書き込んでくれます。
このクエリを用いてPostgreSQLのpgvectorを有効にして、いくつかのテーブルを追加します。
あとはこのActionsを追加すればリポジトリにあるdocsディレクトリのマークダウンのファイルたちをデータベースに書き込んでくれます。
https://github.com/supabase/embeddings-generator
supabaseのクライアントを用いて簡単に検索できます。
const supabaseClient = createClient(
"https://xxxx.supabase.co",
process.env.SUPABASE_SERVICE_ROLE_KEY,
{
db: { schema: "docs" },
},
)
const { error: matchError, data: pageSections } = await supabaseClient.rpc(
"match_page_sections",
{
embedding: embedding.embedding,
match_threshold: 0.78,
match_count: 10,
min_content_length: 50,
},
)
応答を作成する
例えばこのようなプロンプトでお問い合わせの応答を作成します。質問と追加の情報の2つを元に応答を作成しています。
const relatedContents = `育休の延長について
①子どもが1歳の時点で保育園に入れないなどの一定の要件を満たす場合には、子どもが1歳6ヶ月に達する日までの間、育休を延長することができます。
②さらに、子どもが1歳6ヶ月に達した時点で保育園に入れないなどの一定の要件を満たす場合には、最長で子どもが2歳の誕生日を迎える前日までの間、育休を延長することができます。`
const prompt = `
ドキュメントを参照し、その情報のみを使用して、ユーザの質問に応答する。
応答はマークダウン形式で出力されます。
ドキュメントに答えがない場合は「分からない。」的なことを応答します。
Context sections:
${relatedContents. /** 関連するデータ */ }
Question: """
${question /** 質問の内容 */}
"""
Answer as markdown (including related code snippets if available):
シンプルな応答で速度が必要な場合は gpt-3.5-turbo-instruct を使用します。
const data = await openai.completions.create({
model: "gpt-3.5-turbo-instruct",
prompt: prompt,
max_tokens: 1024,
})
これ以降も会話が続くような場合は、過去の質問内容と応答を元に新しいプロンプトを作成します。
const relatedContents = `育休の延長について
①子どもが1歳の時点で保育園に入れないなどの一定の要件を満たす場合には、子どもが1歳6ヶ月に達する日までの間、育休を延長することができます。
②さらに、子どもが1歳6ヶ月に達した時点で保育園に入れないなどの一定の要件を満たす場合には、最長で子どもが2歳の誕生日を迎える前日までの間、育休を延長することができます。`
const customInstructions = `ドキュメントを参照し、その情報のみを使用して、ユーザの質問に応答する。
応答はマークダウン形式で出力されます。
ドキュメントに答えがない場合は「分からない。」的なことを応答します。
====
${relatedContents}
====
`
const messages: ChatCompletionMessageParam[] = [
{ role: "system", content: customInstructions },
{ role: "user", content: "育休を延長できる条件は?" },
{ role: "assistant", content: "子どもが1歳の時点で保育園に入れない場合には1歳6ヶ月まで、子どもが1歳6ヶ月の時点で保育園に入れない場合には2歳の誕生日前日まで育休を延長できます。" },
{ role: "user", content: "1歳2ヶ月の時点では?" },
]
この場合は以下のような応答が得られます。
1歳2ヶ月の時点では育休の延長はできません。育休の延長は、子どもが1歳6ヶ月以上の場合に限られています。